You can split VDP into multiple parts that can be executed in parallel by separate
workers.
To activate this option, select the parameter field Divide Parameters > Create > Single File Part in the Variable Data Printing node. This will
reveal two extra parameter fields:
Divide Document Into Parts: here you can define the
number of parts the job will be divided.
Select part index to output: here you can select which
part of the divided parts the node will use. The range is from 0 to the number
of parts-1. The node will then execute only one part. For example, if you want
to output 1.000 items and divide the output to 4 parts, set the parts index to
2. In that case, the node will output a PDF that contains items from
500 to 750. With this setting, you each of the parts of 0-250, 250-500, 500-750
and 750-1000 are generated with separate workers, which will result in 4 PDF
documents. Once the PDF files are generated, use the Join
Pages node to generate a single PDF.
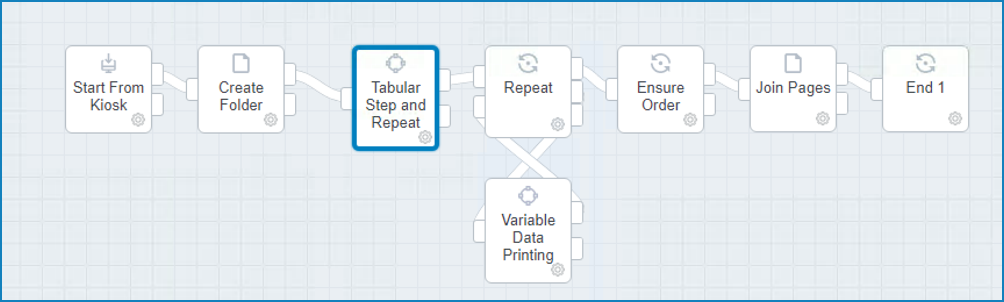
Example workflow:The workflow is creating VDP output from a 1up file, creates the repetition page
using Tabular Step and Repeat and splits the work into multiple parts.
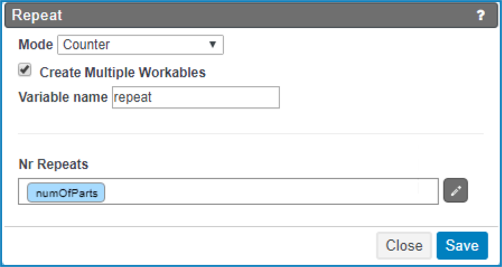
The Repeat node is a simple counter:The repetition is configured with the variable numOfParts, which is a value
entered by user. The Repeat node creates multiple workables, so
the node Variable Data Printing node is executed in parallel,
subject to a number of licensed PACKZFLOW workers.
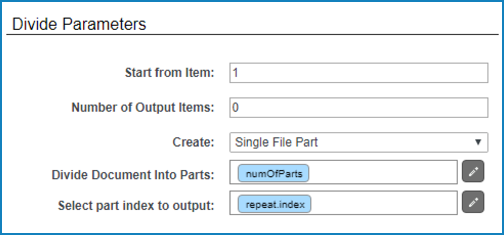
The Divide Parameters section in the Variable Data Printing node
is configured the following way:
Number of Output Items is set to 0, which means
that all records from the database will be output.
Select part index to output is configured with a
subsequent part from the Repeat node.
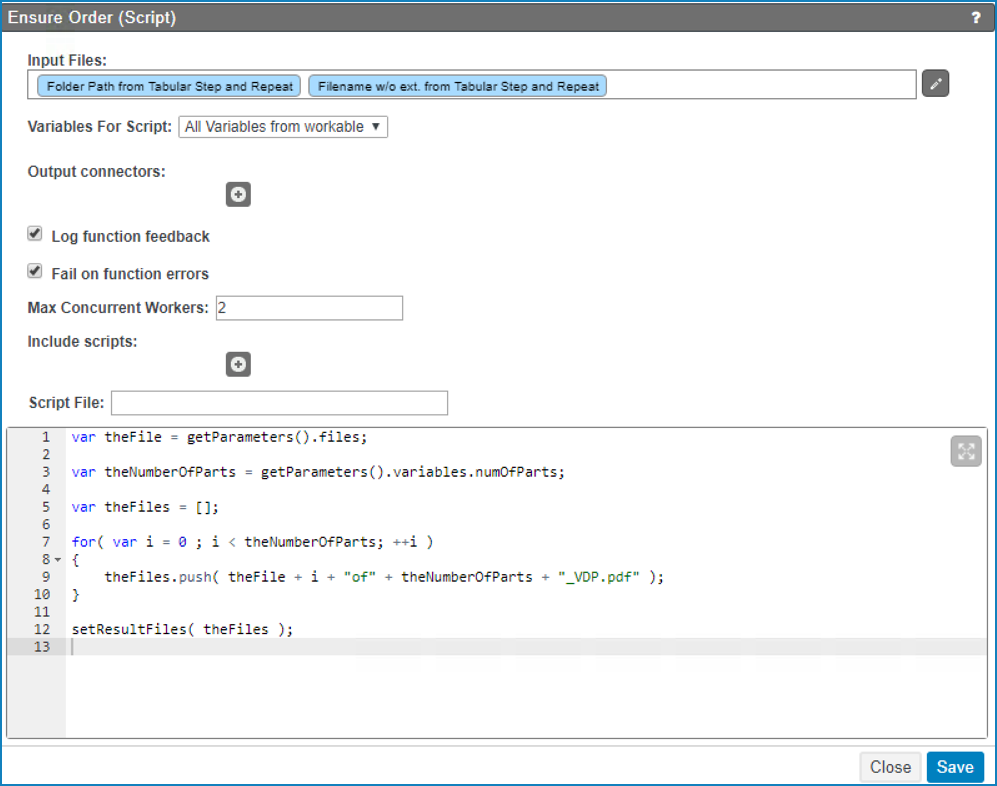
Once all parts are generated, you can use an extra Script node
which will put all PDF output files in a correct order. The Script node has the
following configuration:The configuration will create a list of PDF references in the correct order.
Once the right order is generated, the Join Pages node creates a
single PDF output.
Note:Join Pages is optimized for the output of
a partitioned PDF from the VDP node, so it will process the join very quickly, even
if the PDF parts contain a big number of pages.