Job data
Jobs contain data, such as name, files, Job ID, custom data...
These data can be standard Job data, or custom Job data.
Standard Job data
Standard Job data are saved to the Job via the Create Job node. They are added to the database at Job's data root level.
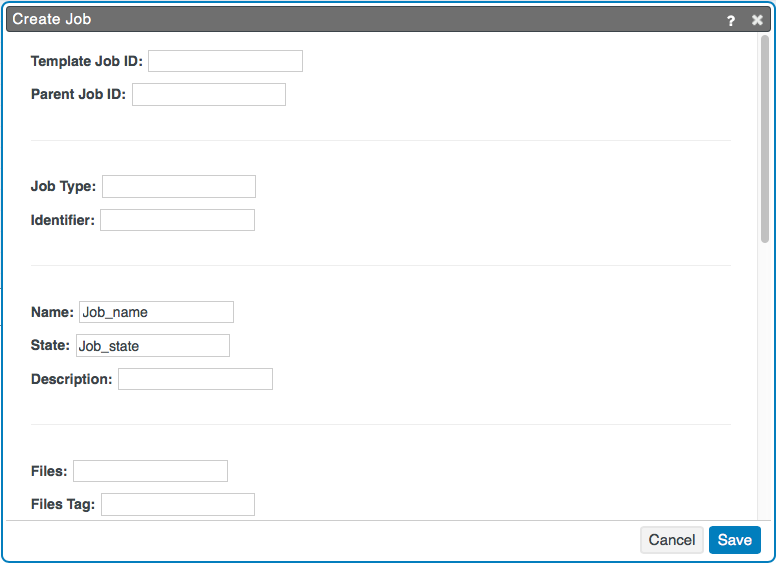
{
"state" : "Job_state",
"name" : "Job_name",
}Custom Job data
Custom Job data should always be saved to the Job in the custom section. You can do this in . You need to define a JSON path that selects an element in the JSON document and a value that you want to set for the specified data path.
Example 1
| Path | Value |
|---|---|
| custom.cusname | CustomerX |
| custom.cusID | 12345 |
| identifier | Job_442542 |
{
"identifier" : "Job_442542",
"custom" : {
"cusname" : "CustomerX",
"cusID" : "12345",
}
}You can also leave the Path empty. In this case, the data are sent to the root level of the Job data in the database.
Example 2
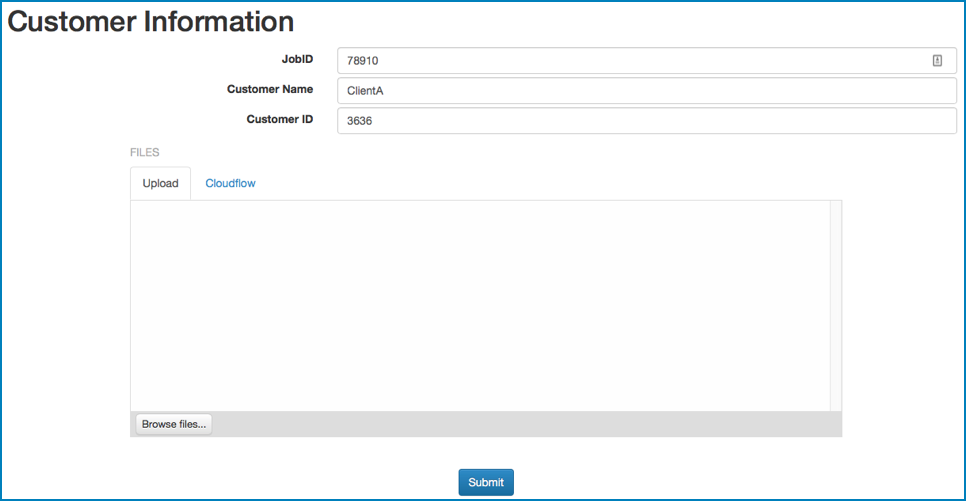
- The JobID key is identifier.
- The Customer Name key is custom.cusname.
- The Customer ID key is custom.cusID.
{
project_data: {
source: "jacket",
value: {
identifier: "78910",
custom.cusname: "ClientA",
custom.cusID: "3636"
}
}
}- identifier is a direct parameter.
- custom.cusname and custom.cusID are custom parameters. It is important to use the dot notation custom.X to add the custom data in the custom section.
You can leave Path empty and define the variable in Value:
| Path | Value |
|---|---|
| project_data |
{
"identifier" : "78910",
"custom" : {
"cusname" : "ClientA",
"cusID" : "3636"
},
}Custom properties per file: best practice
In case you want to add custom properties for each file in the Job, it is best practice to use a nested job object for each file. In that case, one parent Job contains a child Job per file, and you can save the custom data inside the child Jobs:
- Child Job 1
- File data
- Custom data
- Child Job 2
- File data
- Custom data