CLOUDFLOW and virtualization
For ease of IT management, it is recommended to run CLOUDFLOW and MongoDB on virtual machines.
Cloud vs. physical setup
CLOUDFLOW functions perfectly whether hosted on physical servers or on cloud based servers. Both setups support all of CLOUDFLOW's components and infrastructures. When deciding for either one option, the considerations to be made partly relate to the following general advantages and drawbacks:
| Physical | Cloud | |
|---|---|---|
| Server | 1 DEDICATED machine
|
space on SEVERAL shared machines
|
| Performance |
|
|
| Location | On-site. Impact on maintenance, risk, responsibility | Off site. No impact. Maintenance, risk and responsibility covered by provider contract |
| Maintenance | Downtimes inevitable | Limited downtime |
| Access | Operators on-site, no internet required only for cloud | Operators can access from any location that has internet available. |
| Access | No internet access required | Internet access required |
An additional consideration, however, is the concept of Data Locality. Data Locality is the tendency of a processor to reuse similar memory locations repetitively. Such reuse favours memory locations that are neighbours in space and/or time. Conversely, similar datasets that are accessed over time intervals or spatial distances that are too long will lose the benefit of reuse. As a consequence, CLOUDFLOW's data must be kept in closest proximity to its engines, whether in the cloud, locally, or temporally.
This means that sufficient consideration must be given to make the architecture of the CLOUDFLOW setup withstand expected loads and work-flows. Elements to consider as well: network reliability, cable quality, number of operators, mean data load, downtime proneness, etc. where files are stored and where memory see whiteboard
In the case of CF the basic minimal requirement is a user downloading and uploading files from a DB, processing them CF and then re-uploading them (via CF) to the DB. These files are typically large and slow in data traffic.
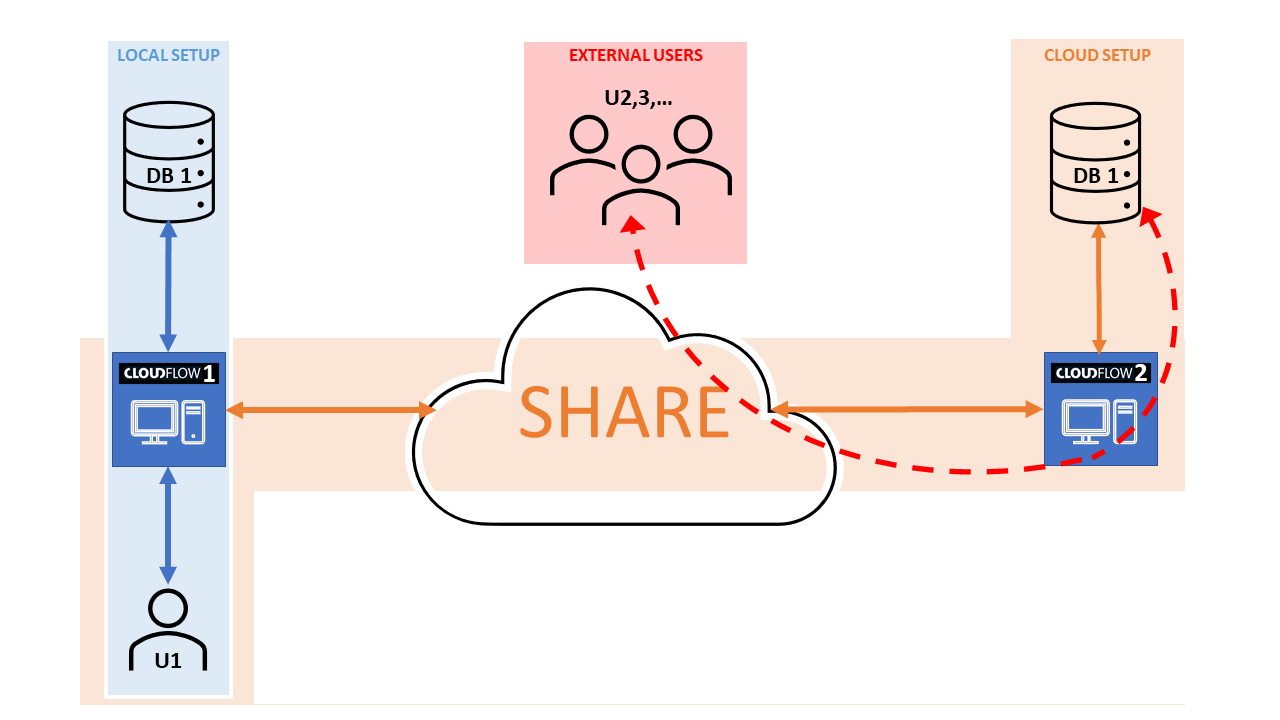
Consider the image above where:
- On the left we have the blue work-flow, a local CF setup with user 1 (U1) interacting with CF1 that in turn interacts with a DB1. As long as user and DB are local, there is no problem.
- In the orange work-flow, U1 is local but DB1 is not local (remote or virtual) and so
both the user and CF1 will be interacting with the remote DB1 and that will require time.
One way to solve this is to increase spatial data locality and deploy another CF instance, CF2, in physical proximity of the remote DB1. That way at least CF2 and DB2 are ‘neighbours’.
User1 won’t experience any drawbacks as his direct partner is still CF1 and even though CF1 connects remotely to CF2 it does so with compressed data packages, which synchronize much more quickly. The technology to share and synchronize information between separate and independent CLOUDFLOW servers across the globe is described in the chapter SHARE.
In more realistic setups requirements are stricter as those will see much more traffic, from many more users.
Assume U2 and U3 want to view and validate U1’s file in Proofscope. Both U2 and U3 are in another physical location. To them all setup elements of solution 2 above are (too) remote: U1, DB1, CF1 and CF2, so that transferring and downloading a file to them directly draws on the system.
However, U2 and U3 do not need the data as soon as U1 has processed the data. The accepted work-flow allows for ample time for the system to send them a notification mail with a link for them to download their file to validate. Or even a notification mail with either a full size file or a compressed one.
CLOUDFLOW setups allow for ample possibilities but the examples above demonstrate that customers’ individual requirements must determine the way the work-flows are conceived so that the architectural landscape can be optimized.
- As long as User+DB+CF are local, the setup is optimal.
- As soon as either CF or DB are not local (cloud, virtual, remote), then the other needs to be deployed there too.
- First work-flows, then setup.
Memory requirements
CLOUDFLOW runs several different sub processes (metadata extraction, thumbnail calculation, pre-rendering for PROOFSCOPE, workflow module, etc...). All these components work together, and each component needs CPU power and memory. Some components (for example the (pre-)RIPping or the pre-press workflow) need sufficient memory to function properly.
On a production CLOUDFLOW system, the CPU often uses close to 100% of its cores and a big chunk of the available system memory. An operating system can handle overdrawing CPU, so if there are more components that want to use the system than the system can handle, performance degrades gracefully. Unfortunately, this is not the case with overdrawing memory. When the total memory consumption exceeds the provided memory, performance drops. This results in an unresponsive and sometimes freezing system.
Therefore, the system needs sufficient memory. See System requirements for the CLOUDFLOW Application server for the recommended minimum requirements.
Combining systems on one host
Adding a virtualization layer to the hardware causes a performance hit.
Depending on the technology this can be small (5%) or large (30%). One of the drivers of virtualization is making better use of hardware, by combining multiple guest systems on one host.
However, since CLOUDFLOW is designed to extract all the performance it can get from the underlying system (by making heavy use of multi-threading and multi-processing), it is at odds with other virtual guests competing for the same performance of the underlying host.
Only when the underlying hardware is very highly spec'ed, this argument becomes less of an issue (for example 16-core servers with 256GB RAM).
3D and OpenGL limitations
It is not possible to use CLOUDFLOW's 3D capabilities when running on top of a virtualization software (like VMWare, Hyper-V, ...).
CLOUDFLOW's 3D rendering technology uses OpenGL 3.2 or higher. This is, to our current knowledge and field trials, not supported by current visualization technologies.
If CLOUDFLOW 3D technology is used, it is recommended to run the software non-virtualized on a hardware platform with 3D capabilities and a graphics driver that offers the Open GL 3.2 API for the installed operating system.